
立即扫码
享受一对一服务

发布时间:2019.02.26来源:亿信华辰浏览量:165次标签:数据治理
今天我们主要来说一下典型技术架构的分析和构建。这是我们实操的第一步。
典型技术架构的分析和构建
可能听了我的分享或者别人的分享,大家都会跃跃欲试。我们需要从哪一个方面去入手去改造大数据业务呢?我整理了一下,一个大数据应用的一个完整流程,其实是分4个步骤,在我这儿看是4个步骤。
第一个流程是数据的汇总。
数据的汇总其实是通过各种各样的方式把数据源的数据做一个整合或者哪一个平台里面。把所有的数据能够打通都打通,能把数据整合到一个池子里面的都整合到一个池子里面,至于这个打通的渠道和通道是什么,以及这个池子是什么,我后一步会去说,但是你要第一步去思考这个问题,你手上有什么数据你先搞搞清楚。这是大数据的第一步,数据汇总。你得汇总什么,你得要一个明确的概念。
第二步,数据清洗。数据汇总完了以后,我们要对数据进行一个清洗,就是这一步是我刚刚说的可以省略的一步,因为有一些同学他的业务比较单纯或者相对来说数据比较标准化,没有太多的一些需要清洗的东西,他能直接应用在大数据应用和开发里面,这个看你的业务需要,清洗不是一个必须的过程,可做可不做。
正常来说,大部分的数据都要去做一次或者多次的清洗。那么对汇总数据进行清洗主要是筛掉一些没有用的信息,然后将数据转化成可读性高一点的、关联完整度高一点的数据。因为我们很多很多数据来源于不同的系统,来源于不同的业务,甚至来源于不同的数据库。这种情况下你的数据过来之后会导致一个问题,因为你本身是从各个数据孤岛过来的,那你原先可能是通过各种各样的ID去关联或者是通过各种各样的消息ID或者是任务ID去关联,其实这种关联是挺碎的,需要在一个合理的范围内去把这些数据去打平。我们上一期内容也着重说了一个打平的内容,我觉得打平是数据清洗一个比较核心的点,就是多表打平,就是做一个宽表的概念是比较重要的,甚至它占到数据清晰50%以上重要度,这是我个人的理解。因为你只有把它打平之后,它的可利用率才高,而不是说东一块西一块的,这个数据放在各个不同的区块里面或者是还要通过各种关联问题才可以查到,这种对我们后续去运用这个大数据的时候,会带来很多很多的不方便,效率会很低,对开发人员的要求会变的很高。
第三步,数据计算。
完成数据清洗之后,我们可以通过各种各样的方式去计算,去做一个数据的深加工。做深加工的目的是什么呢?为了把数据的价值更好的体现出来,你要去打一个比较好的基础,我觉得数据计算这一步是整个大数据算是一个灵魂。因为你清洗完的数据其实也不具备什么的价值,你无非是把各个系统的数据打通,然后清洗到几张宽表里面,那么最终这些宽表数据意味着什么呢?产生什么呢?能挖掘出什么呢?有这些东西都是由数据计算去决定的,所以数据计算是整个大数据应用核心一个灵魂。
第四步数据应用。
我们在数据加工完成之后,为一项或者多项加工成果披上外衣,把它变成一个可以让用户使用或者是可以被用户感知到的一个具体应用或者是功能模块。这是我觉得大数据应用你前面三个流程做完以后,最后一个产出物,就相当于我们从树上摘一个果子,然后把这个果子洗干净,洗干净之后我们通过一系列的加工手段,把它加工成一个糖水罐头,然后我们最终把这个糖水罐头送到用户面前让他去吃,他觉得这个东西好吃,这个就达到效果了。
这是我觉得这个大数据应用是这样一个流程,4步。打个比方,有的果子可能是在无菌环境下生长的,所以它很干净不需要清洗,那可能就省掉了第二步,那就直接从树上采下来之后放在加工中心,加工完去生产出一个罐头给到用户去吃,那这个可能会把数据清洗这一环省掉。但是我觉得大部分,绝大部分的公司可能数据清洗这一步都是需要去做的。所以大家不需要太纠结这个过程,但是理论上来说都是这4步都要走的,而且应该是按顺序去走的。
数据汇总-清洗-计算-应用四步如何走?
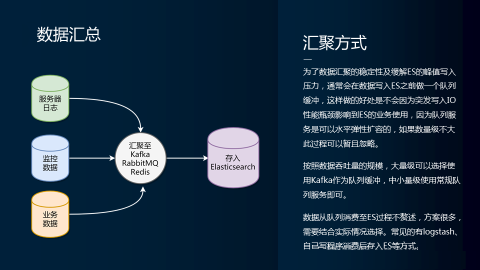
我们先说一下数据汇总,数据汇总我们前面说过我们的数据来源有几块,一个是服务器的日志或者是我们的监控数据或者是我们业务数据,乃至更多数据渠道。这个可以大家发挥自己的想象力,把它串联起来。
为什么要这样去做呢?大家看我们在这个圆形的图式中,写了哪些字:Kafka Rabbit MQ Redis,都是一些像消息队列一样的一些工具或者是平台。那么原因是什么呢?因为我们要估量出数据的规模,我们不能直接把数据,未清洗的数据直接统一导到某一个数据池也好,数据库也好。不能直接去导原因是什么?很简单的一个道理。就是我们任何一个数据库或者是数据池都是有性能上限的,特别是它应用在业务中的时候,可能正在被查询,可能正在进行生产或者是正在进行模型训练等等这样一些事情。那么这个过程中,如果你有突发的数据过来,因为对数据的吞吐量你是没有办法去预测的,所以有突发的数据过来可能会影响到你正在生产或者是正在操作的数据库的稳定性。所以我们在中间放了一套缓冲机制,把所有的信息投递到我们消息队列,然后再由消费消息队列的方式去把数据读出来,然后存到我们原始数据池中去。我这儿写的原始数据池写的是ES。
但是具体你的业务使用环境或者是过程中是不是使用ES,你自己去考量,并不一定是绝对,只是我用顺手了,所以我更喜欢用ES,因为它比较方便。这是汇聚方式。其实主要还是为了这种汇聚方式,这个架构主要目的为了提高我们数据池的一个稳定性。然后削平峰谷这是一个比较好的弹性方案,不会因为突发写入IO性能瓶颈影响到整个ES的业务使用,影响到这个数据库的使用。而且我们现在大部分队列服务都是分布式的,也可以去水平扩容,做储存等等,就各种各样的方式就相对来说它的抗压能力会比一个常规的数据库要强一些。
那至于说我从这一步导向这一步的过程我就不赘述了,其实方案挺多的,但是你可能要根据实际的情况去选择,比较常见的有logstash或者是我们自己写一个程序去消费队列,去消费kafka,消费redis或者是MAS,消费之后把它存到我们的ES里面去,这样一种方式。因为这个过程可以选择的工具链以及方案很多,而且差异性很强,所以我没有办法去给大家画一张这个区域的图,这个区域的图相对来说比较简单,就消费存入就行了,就各家有各家的方案去处理,但是万变不离其宗,不是一个高难度的操作。这是我们的一个汇聚方式。
说完汇聚方式之后,我们说一下就是数据清洗,数据清洗就是我们刚刚说我们拿到了一个原始大数据池,比如说ES,我们需要对它进行清洗。
清洗主要做几件事情。一个是清洗掉没有用的字段或者是过滤不符合预期的数据,直接表现为我们有一些日志中的数据,它可能跟我们业务没有什么太大的关系,只是纯粹是一些CPU的数据或者是内容的占用率或者是磁盘占用率,可能这些数据大部分公司是不需要,大部分公司只需要把这些属于给到监控室就可以了,不需要把它搀和到我们大数据计算这个过程中。所以在这个环节我们可以把这部分的数据清洗掉,过滤掉,只留下我们想要的一些数据。
第二个就是统一字段类型和格式。这个阶段主要做的内容是哪些,我下面举了个小例子,比如说我们java的时间戳是13位,PHP的时间戳为10位,这种情况下,要么你把13位最后面3位抹掉,降低它的精度,要么你是把PHP的时间戳后面再补三个0提高它的精度,让它变成13位的。一定要做成统一格式,做成标准化的,要么你全系统都是13位,要么都是10位。如果你不补0补到13位或者降低精度变成10位,它在后续使用过程中会出现很多奇奇怪怪的问题,因为你的数据预期不一样,所以表示年月日或者是换算年月日的时候最后算出来的数据是不一样的,可能对你的业务来说会多很多的逻辑错误。这个例子可能最好理解的例子了,就是时间戳补0或者是降低精度的问题,主要是为了统一我们的字段类型和格式。
有的系统里面我的字段类型可能是数据性或者是字符串类型的。我们需要在我们的清洗过程中,把它统一的转化成一样的格式,或者说我们有一些小数点类型,我们在精度上有要求的,这一步就要统一的清洗好,就是这一块。
那么完成格式和字段类型的清洗和调整之后,我们需要把关联表打平到单表,就是合成宽表,这个就是我们上一期内容主要讲的内容,做宽表的目的是为了让我们后期使用这个数据的时候能够在一个较低的成本下去应用到更多的有效数据。因为比如说当我们想要去用一个数据的时候,如果我还要产生很多的关联查询,在大数据应用的时候去产生很多的关联查询,会影响到我们的效率,一定产生关联查询还会产生一个更大的问题,就是你的数据池的性能以及你的数据标准化做的是不是好,你的关联出来的数据是否准确等等一系列的问题都要考虑。相当你把一个简单的问题可以在前期做好预防工作就可以避免的问题,留到了后期变成了一个麻烦。所以我觉得这个是一个很重要的一个。所以我打一个五角星,我觉得这个是比较重要的一环。
那么下面我简单提炼了一下,数据清洗的意义不是单纯过滤掉无用的信息或者是统一一下格式。因为它更多是完成前置,就是一定要把这个事情做在前面,前置的完成关联关系的处理。比如说我们现在有几张表,用户,商品,订单表,三张表。如果是我们各自独立的,在后期我们去应用它的时候会出现性能瓶颈,就是我刚刚说的关联查询等等。还会大幅度提高数据计算逻辑复杂性,就是我们写一个运算算法的人或者是写这个逻辑代码的人,他脑子会比较痛,也许他这个人并不是很懂业务,他可能是一个纯技术人员,他不一定很懂业务,他还要去找各个相关岗位去问这个表,这个字段,这个数据有什么含义,跟我们业务结合的时候有什么用等等,就是会提高他的工作复杂程度。所以我们会把多张表打平到一层,制作一张宽表来容纳三个表所有的字段。
举个例子,我有用户表、商品、订单表,通常会是打平的时候会用最末端的一张表来打平,也就是说用订单表来打平。那有的人说为什么不用商品表或者是用户表来打平。因为最终会进到池里面的时候,我们是太在意这个数据的量级和大小,我只在意这个数据的完整性。也就是说在这个订单表里面可能有一件商品卖给了10万人,那就会产生10万个订单,如果你以订单表去作为打平的对象的话,那会产生一个大量的数据冗余,也就是说你的订单表只有5个字段,订单、用户ID、创建订单时间、数量、单价、总价,这几个字段,但是一旦跟用户表和商品表整合进去之后这个宽表就会变的很宽,可能会变成50个字段甚至100个字段,这个情况下是合理的,这个方式跟我们常规的开发是不太一样,也不能说我们,就是我的实际应用过程中我更提倡大家在这一步去把这个宽表一次性打到位。哪怕说明明三张表可能加起来只有5个G数据,这样一清洗一搞就变成了50个G数据,我觉得没有关系的,我觉得我能接受。因为你这样后期你应用的时候你会很爽,订单号可以带出来订单号所有的数据,这个订单号是跟哪一个用户关联的,张三李四,然后关联的是什么商品,那么衣服手表还是包包,这些都可以弄出来,可以统一弄出来,这样后期去做的时候就会很方便,所以这个是我们打平的逻辑。
那么当我们的数据清洗完成之后,再讲一下漏掉了,就是数据清洗几个方向,我们刚刚前面这一页说的,三件事情,我们有几个方向去做呢?第一个是标准化,标准化就是我刚刚说的把字段格式统一,然后把逻辑做好,关联做好,这叫标准化。然后做减法是什么含义呢?我们那个数据会有冗余会有繁杂的部分,所以这部分数据是我们不需要的,就比如说我们前面刚刚说的CPU的占用率内存的占用率,这些数据其实我们是用不到的,这些数据可以在这个地方去做减法,减掉。还有一种情况就是做清洗的时候,我们需要去做加法。做加法是什么含义呢?就是说我清洗之前,可能这张表只有15个字段,清洗完成之后可能会有25个字段,这样是怎么去产生的。举个最简单的例子,这也是我上一期内容里面讲过的,就是说我们去清洗这个字段叫IP地址,我可以通过IP地址一个字段去延伸出来至少3,4个字段,一个是你IP地址本身,然后IP地址本身还有运营商,因为IP地址可以查到你的运营商,然后你的国家、省份、地市一级、区县一级,甚至现在更精确可以查到IP地址所在街道,但是这个准不准我不知道,但是至少至少你可以围绕IP地址去做五六个字段的加法,这是我觉得很有意义的事情。因为相当于你扩充了数据的维度,本身IP地址只是一串数字,本身没有什么具体的含义,只是说一个人在网络上身份一个标识而已。但是你通过这个方式,可以让这个数据维度更多了,首先多了运营商的维度,还多了地理位置的维度,这些维度可以让你在后期去做大数据计算的时候有更多依据一个方式和方法。这是我觉得做清洗最主要三个方向。
清洗完了之后我们还需要去做数据计算,这是数据计算就是我们第三块灵魂。我们可以分两条线去看,一个是我们阿里云路线走法和我们开源路线的一个走法。
第一个我们先说一下我们有效数据池,有效数据池就是我们刚刚说的清洗数据完成之后得到一个有效数据池,这个有效数据池可以是ES也可以是其他的,这个随你喜欢就好,你觉得可以胜任场景和性能要求,你就可以去换别的。

数据计算完成之后,会进入到最后一个环节,就是数据应用,那么数据应用有几个方面。第一个你可以去基于大数据去做一些浅层的机器学习,就是简单的机器学习,挖掘更多的业务价值,就是基于你原有的业务数据和用户行为,偏好等等这些数据,你可以去做挖掘,浅层的挖掘。比如说是电商和媒体,因为我本身是做媒体的,可以基于用户行为数据去做智能推荐,这个方案很多,甚至很多教程都有的,这种方式可能是成本最低,也是对业务帮助立竿见影的一种方式。除了这种方式以外,我们还可以说基于历史的交互数据,比如说我们汽车里面有记录汽车信息的模块,其他的设备里面有记录各种设备操作的日志等等,基于这些数据去做深度学习去开发一个定向垂直AI类的应用,我觉得也是没问题的。特别是像现在智能客服挺火的,像文字类客服,基本上是可以做到以假乱真,基本你去咨询问题,你是感受不到跟你聊天的客服是真人还是机器人,但是背后还是有一些深度学习的内容在里面。还有一个是自动驾驶,这个不用我说大家都比较清楚,像特斯拉等等之类的。
第三个就是说把所有业务数据全部唤醒,然后实施可视化,把数据直观展现出来,让所有人感知数据。其实这一块比较好理解,这种常见数据像我们数据报表,数据化大屏,可视化大屏,就这些都是这种类型的应用很多的,这也是一个实施周期短,然后立竿见影的一个方向。
然后第四个基于行业大数据和模型调测去做一些预测分析,这个可能看各个行业的情况不同,可能能做的事情也不一样。比如说像气象领域去预测一下台风的行走路径,或者是台风发生的概率,下雪的概率。像交通可以预测一下什么什么时间段,这个路有什么规模的车流量,会不会拥堵,以便于他及时的去调配红绿灯,这些也都是比较成熟应用的案例。
数据应用的方向讲完之后,那我们整体回顾一下我们方案内容,架构的内容,就像我刚刚说的,前面就像我说的这一层,我们前面这一层业务数据、监控数据、服务器日志这一块汇聚到消息队列,然后从消息队列消费到原始数据池中去。然后在原始数据池中的基础上去做一次清洗,清洗完了之后把数据存入到我们有效数据池,也就是说原始数据池和有效数据池是隔离的。有效数据池完了之后,把数据导入到我们大数据池中去,比如说HBase或者是ODPS这一块。那么导入进去之后我们可以再通过离线计算还有留计算,机器学习,深度学习等等去开发我们应用。也就是说我们全程,我们可能会用到三块数据库,一个是我们原始数据池数据库,一个是有效数据池数据库,然后我们大数据池一个数据库,也就是说我们会有三个数据池。
那么有的人可能会说,那这样搞来搞去好像成本和维护代价太高了,那有一个简单的方式可以告诉大家,就是说我们原始数据池和有效数据池可以合并成一个。无非就是一个清洗完了之后重回到本身就可以了。但是我把它分开的一个原因是,我们踩过一些坑,就是你一层递进这样是最安全的,你不会因为说性能可靠性或者是一些这样那样的网络问题导致的风险去影响到线上业务,主要是一个考虑,这个是从安全性和稳定性去考虑我们会有三块数据池。但是你从最小可用角度来说,你甚至可以直接把原始数据写到大数据池里面,然后再大数据池里面去做清洗,还有打平这些事情都在大数据池里面做也没事,具体去看,按照你自己需求和场景去进行一些调整就可以了。

发布时间:2020.03.26来源:知乎浏览量:197次
发布时间:2018.12.07来源:浏览量:260次
发布时间:2021.06.24来源:亿信数据治理知识库浏览量:225次
发布时间:2019.03.19来源:亿信华辰浏览量:197次
发布时间:2019.01.04来源:亿信华辰浏览量:225次
发布时间:2020.08.31来源:亿信华辰浏览量:195次
发布时间:2020.04.03来源:知乎浏览量:196次
发布时间:2019.12.12来源:知乎浏览量:194次
发布时间:2021.04.26来源:亿信数据治理知识库浏览量:289次
发布时间:2019.03.26来源:亿信华辰浏览量:190次
保存二维码微信扫一扫,立即在线咨询
人工
客服
预约
演示
您好,商务咨询请联系
400咨询:4000011866
技术
支持
您好,技术支持请联系
QQ:400-0011-866
(工作日9:00-18:00)