
立即扫码
享受一对一服务

发布时间:2019.03.20来源:数据清理浏览量:181次标签:数据治理

我花了几个月的时间分析来自传感器、调查及日志等相关数据。无论我用多少图表,设计多么复杂的算法,结果总是会与预期不同。更糟糕的是,当你向首席执行官展示你的新发现时,他/她总会发现缺陷,你的发现与他们的理解完全不符- 毕竟,他们是比你更了解领域的专家,而你只是数据工程师或开发人员。
你为你的模型引入了大量脏数据,没有清理数据,你告诉你的公司用这些结果做事情,结果肯定是错的。数据不正确或不一致会导致错误的结论,因此,清理和理解数据对结果的质量都会有很大影响。
垃圾进垃圾出
实际上,简单算法的作用可能超过复杂的算法,因为它被赋予了足够高质量的数据。
质量数据优于花哨的算法
出于这些原因,重要的是要有一个分步指南,一个备忘单。首先,我们想要实现的目标是什么?质量数据是什么意思?质量数据的衡量标准是什么?了解你想要完成的任务,在采取任何行动之前,你的最终目标至关重要。
目录:
· 数据质量(合法性,准确性,完整性,一致性)
· 工作流程(检查,清洁,验证,报告)
· 检查(数据分析,可视化,软件包)
· 清理(无关数据,重复数据,类型转换,语法错误)
· 验证
· 总结
数据质量
除了维基百科上的质量标准之外,我找不到更好的解释质量标准。所以,我将在这里总结一下。
合法性
数据符合定义的业务规则或约束的程度。
· 数据类型约束:特定列中的值必须是特定的数据类型,例如,布尔值,数字,日期等。
· 范围约束:通常,数字或日期应在特定范围内。
· 强制约束:某些列不能为空。
· 唯一约束:字段或字段组合在数据集中必须是唯一的。
· Set-Membership约束:列的值来自一组离散值,例如枚举值。例如,一个人的性别可能是男性或女性。
· 外键约束:在关系数据库中,外键列不能具有引用的主键中不存在的值。
· 正则表达式模式:必须采用特定模式的文本字段。例如,电话号码可能需要具有模式(999)999-9999。
· 跨领域验证:跨越多个领域的某些条件必须成立。例如,患者出院的日期不能早于入院日期。
准确性
数据接近真实值的程度。
虽然定义所有的值允许出现无效值,但这并不意味着它们都是准确的。
一个有效的街道地址可能实际上并不存在,一个人的眼睛颜色,比如蓝色,可能是有效的,但不是真的。另一件需要注意的是精度和精度之间的差异。
完整性
所有必需数据的已知程度。由于各种原因,数据可能会丢失。如果可能的话,可以通过质疑原始来源来缓解这个问题,比如重新获得这个主题的数据。
一致性
数据在同一数据集内或跨多个数据集的一致程度。当数据集中的两个值相互矛盾时,就会出现不一致。
离婚后,有效年龄,例如10岁,可能与婚姻状况不符。客户被记录在具有两个不同地址的两个不同表中。哪一个是真的?
工作流程
工作流程一共四个步骤,旨在生成高质量的数据,并考虑到我们所讨论的所有标准。
1.检查:检测不正确和不一致的数据。
2.清洁:修复或删除发现的异常。
3.验证:清洁后,检查结果以验证是否正确。
4.报告:记录所做更改和当前存储数据质量的报告。
实际上,你所看到的顺序过程是一个迭代的,无穷无尽的过程。当检测到新的缺陷时,可以从验证到检查。
检查
检查数据非常耗时,并且需要使用许多方法来探索用于错误检测的基础数据。下面是其中的一些:
数据分析
一个汇总统计有关数据的数据分析是真正有用的,它可以提供有关数据质量的总体思路。例如,检查特定列是否符合特定标准或模式。数据列是记录为字符串还是数字?丢失了多少个值?列中有多少个唯一值及其分布?此数据集是否与另一个数据集链接或有关系?
可视化
通过使用诸如平均值、标准偏差、范围或分位数等统计方法分析和可视化数据,可以找到意外且因此错误的值。
例如,通过可视化各国的平均收入,可能会看到有一些异常值。这些异常值值得研究,不一定是不正确的数据。
软件包
使用你的语言提供的几个软件包或库将允许你指定约束并检查数据是否违反这些约束。此外,他们不仅可以生成违反哪些规则的报告,还可以创建哪些列与哪些规则相关联的图表。
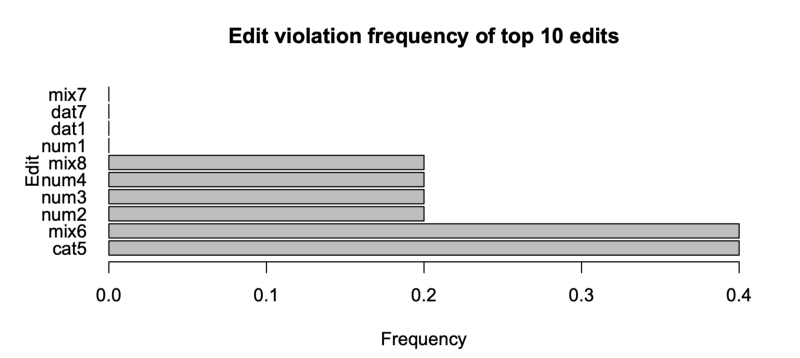
清洁
数据清理涉及基于问题和数据类型的不同技术。可以应用不同的方法,每种方法都有自己的权衡。总的来说,不正确的数据被删除,纠正或估算。
不相关的数据
不相关的数据是那些实际上不需要的数据,并且不适合我们试图解决的问题。例如,如果我们分析有关人口总体健康状况的数据,则不需要电话号码。同样,如果你只对某个特定国家/地区感兴趣,则不希望包含所有其他国家/地区。只有当你确定某个数据不重要时,你才可以放弃它。否则,你就需要探索特征变量之间的相关矩阵。
即使你注意到没有相关性,你应该问一个域专家。你永远不会知道,一个似乎无关紧要的特征,从实际经验来看,可能非常重要。
重复项
重复项是数据集中重复的数据点。
例如:
· 数据来自不同来源;
· 用户可能会两次点击提交按钮,认为表单实际上没有提交;
· 提交了两次在线预订请求,纠正了第一次意外输入的错误信息。
类型转换
确保将数字存储为数字数据类型,日期应存储为日期对象,或Unix时间戳(秒数),依此类推。如果需要,可以将分类值转换为数字和从数字转换。
需要注意的是,无法转换为指定类型的值应转换为NA值(或任何值),并显示警告。这表示值不正确,必须修复。
语法错误
删除空格:应删除字符串开头或结尾的额外空格。
" hello world " => "hello world
填充字符串:字符串可以用空格或其他字符填充到一定宽度。例如,某些数字代码通常用前缀零表示,以确保它们始终具有相同的位数。
313 => 000313 (6 digits)
拼写错误:字符串可以通过多种不同方式输入,毫无疑问,可能会出错。
Gender
m
Male
fem.
FemalE
Femle
这个分类变量被认为有5个不同的类,而不是预期的2个:男性和女性。因此,我们的职责是从上述数据中识别出每个值是男性还是女性。我们可以怎么做呢?
第一种解决方案是手动将每个值映射到“男性”或“女性”。
dataframe['gender'].map({'m': 'male', fem.': 'female', ...})
第二种解决方案是使用模式匹配。例如,我们可以在字符串的开头查找性别中m或M的出现。
re.sub(r"\^m\$", 'Male', 'male', flags=re.IGNORECASE)
第三种解决方案是使用模糊匹配:一种算法,用于识别预期字符串与给定字符串之间的距离。它的基本实现计算将一个字符串转换为另一个字符串所需的操作数。
Gender male female
m 3 5
Male 1 3
fem. 5 3
FemalE 3 2
Femle 3 1
此外,如果你有一个像城市名称这样的变量,你怀疑拼写错误或类似字符串应该被视为相同。例如,“lisbon”可以输入为“lisboa”,“lisbona”,“Lisbon”等。
City Distance from "lisbon"
lisbon 0
lisboa 1
Lisbon 1
lisbona 2
注意“0”,“NA”,“无”,“空”或“INF”等值,它们可能意味着同样的事情:缺少价值。
规范
我们的职责是不仅要识别拼写错误,还要将每个值放在同一标准格式中。对于字符串,请确保所有值都是小写或大写。
对于数值,请确保所有值都具有特定的测量单位。例如,高度可以是米和厘米。1米的差异被认为与1厘米的差异相同。因此,这里的任务是将高度转换为单个单位。
对于日期,美国版本与欧洲版本不同。将日期记录为时间戳(毫秒数)与将日期记录为日期对象不同。
缩放/转换
缩放意味着转换数据以使其适合特定的比例,例如0-100或0-1。
例如,可以将学生的考试分数重新缩放为百分比(0-100)而不是GPA(0-5)。
它还可以帮助使某些类型的数据绘图更容易。例如,我们可能希望减少偏斜以帮助绘图(当有这么多异常值时)。最常用的函数是log,square root和inverse。缩放也可以在具有不同测量单位的数据上进行。
规范化
虽然规范化也将值重新调整为0-1的范围,但目的是转换数据以使其正常分布。为什么?
因为在大多数情况下,如果我们要使用依赖于正态分布数据的统计方法,我们会对数据进行标准化。怎样完成?
可以使用日志功能,也可以使用其中一种方法。
根据使用的缩放方法,数据分布的形状可能会发生变化。例如“标准Z分数”和“学生t统计量”保留了形状,而日志功能则没有。
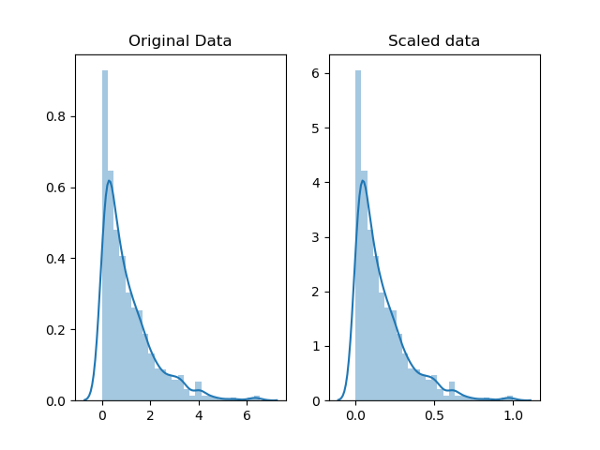
规范化与缩放(使用特征缩放)
缺失值
鉴于缺失值是不可避免的,让我们在遇到它们时该怎么做。有三种或许更多的方法来处理它们。
一、Drop
如果列中的缺失值很少发生并且随机发生,那么最简单和最正确的解决方案是删除具有缺失值的观察值(行)。如果缺少大多数列的值,并且随机发生,则典型的决定是删除整列。
这在进行统计分析时特别有用。
二、Impute
这意味着根据其他观察结果计算缺失值。有很多方法可以做到这一点:
1、使用统计值,如均值,中位数。但是,这些都不能保证获得无偏的数据,特别是在有许多缺失值的情况下。
当原始数据不偏斜时,平均值最有用,而中值更稳健,对异常值不敏感。在正态分布的数据中,可以获得与均值相差2个标准偏差的所有值。接下来,通过生成之间的随机数填写缺失值(mean — 2 * std) & (mean + 2 * std):
rand = np.random.randint(average_age - 2*std_age, average_age + 2*std_age, size =count_nan_age) dataframe["age"][np.isnan(dataframe["age"])] = rand
2、使用线性回归。根据现有数据,可以计算出两个变量之间的最佳拟合线,比如房价与面积m2。值得一提的是,线性回归模型对异常值很敏感。
3、Hot-deck:从其他类似记录中复制值。这仅在你有足够的可用数据时才有用。并且,它可以应用于数值的且已经分类的数据。
另外我们还可以采用随机方法,用随机值填充缺失值。进一步采用这种方法,可以先将数据集分成两组,基于某些特征,比如性别,然后随机分别填写不同性别的缺失值。
三、Flag
一些人认为,无论我们使用何种插补方法,填写缺失值都会导致信息丢失。这是因为说缺少数据本身就是信息性的,算法知道它。当丢失的数据不是随机发生时,这一点尤为重要。举一个例子,一个特定种族的大多数人拒绝回答某个问题。
丢失的数据可以用例如0填充,但在计算任何统计值或绘制分布时必须忽略这些零。虽然分类数据可以用“缺失”填写:一个新的类别,它告诉我们缺少这一数据。
离群(极端)值
它们的值与所有其他观察值显著不同。远离Q1和Q3四分位数的任何数据值(1.5 * IQR)都被认为是异常值。
在被证明之前,异常值是无辜的。话虽如此,除非有充分理由,否则不应删除它们。例如,人们可以注意到一些不太可能发生的奇怪的,可疑的值,因此决定将它们删除。虽然,他们值得调查之前删除。
值得一提的是,某些模型,如线性回归,对异常值非常敏感。换句话说,异常值可能会使模型脱离大多数数据所在的位置。
记录和交叉数据集错误
这些错误是由于在同一行中有两个或多个值,或者是在彼此相互矛盾的数据集中。例如,如果我们有一个关于城市生活成本的数据集。总列数必须等于租金,运输和食物的总和。同样,孩子不能结婚。员工的工资不能低于计算的税额。相同的想法适用于不同数据集的相关数据。
验证
完成后,应通过重新检查数据并确保其规则和约束确实存在来验证正确性。
例如,在填写缺失数据后,它们可能违反任何规则和约束。如果不可能,可能会涉及一些手动校正。
报告
报告数据的健康程度对清洁同样重要。如前所述,软件包或库可以生成所做更改的报告,违反了哪些规则以及多少次。
除了记录违规外,还应考虑这些错误的原因。为什么他们发生?
总结
我很高兴你能坚持到最后。但是,如果不接受质量文化,所提到的内容都没有价值。
无论验证和清理过程多么强大和强大,随着新数据的进入,我们必须将继续受苦。最好是保护自己免受疾病的侵害,而不是花时间和精力去补救它。

发布时间:2019.01.11来源:亿信华辰浏览量:172次
发布时间:2020.09.29来源:头条浏览量:188次
发布时间:2021.03.23来源:亿信数据治理研究院浏览量:750次
发布时间:2019.08.15来源:知乎浏览量:181次
发布时间:2019.01.17来源:亿信华辰浏览量:316次
发布时间:2019.01.07来源:亿信华辰浏览量:189次
发布时间:2020.06.30来源:知乎浏览量:162次
保存二维码微信扫一扫,立即在线咨询
人工
客服
预约
演示
您好,商务咨询请联系
400咨询:4000011866
技术
支持
您好,技术支持请联系
QQ:400-0011-866
(工作日9:00-18:00)