
立即扫码
享受一对一服务

发布时间:2019.02.20来源:亿信华辰浏览量:360次标签:数据治理
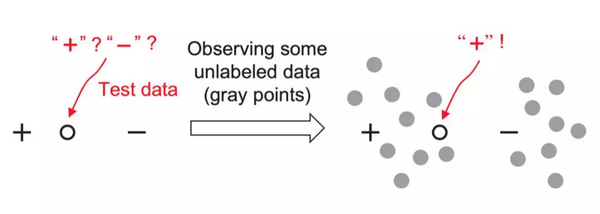
在击败 11 个 NLP 任务的 State-of-the-art 结果之后,BERT 成为了 NLP 界新的里程碑, 同时打开了新的思路: 在未标注的数据上深入挖掘,可以极大地改善各种任务的效果。数据标注是昂贵的,而大量的未标注数据却很容易获得。
在分类中,标签表示训练示例所属的类; 在回归中,标签是对应于该示例的实值响应。 大多数成功的技术,例如深度学习,需要为大型训练数据集提供 ground truth 标签;然而,在许多任务中,由于数据标注过程的高成本,很难获得强有力的监督信息。 因此,希望机器学习技术能够在弱监督下工作。
这不可避免地导致我们重新考虑弱监督学习的发展方向。 弱监督学习的主要目标是仅使用有限量的标注数据,和大量的未标注数据,来提升各项任务的效果。
弱监督最大的难点在于如何用少量的标注数据,和为标注数据来有效地捕捉数据的流形。目前的一些解决方案在面对复杂的数据时,比较难准确地还原数据的流形。但是 BERT 通过大量的预训练,在这方面有着先天的优势。
因而,BERT 凭借对数据分布的捕获是否足以超越传统半监督的效果?又或者,BERT 能否有与半监督方法有效地结合,从而结合两者优势?
弱监督
通常,有三种类型的弱监督。第一种是不完全监督,即只有一个(通常很小的)训练数据子集用标签给出,而其他数据保持未标注。 这种情况发生在各种任务中。 例如,在图像分类中,ground truth 标签由人类注释者给出;很容易从互联网上获取大量图像,而由于人工成本,只能注释一小部分图像。
第二种类型是不精确监督,即仅给出粗粒度标签。 再次考虑图像分类任务。 期望使图像中的每个对象都注释;但是,通常我们只有图像级标签而不是对象级标签。
第三种类型是不准确监督,即给定的标签并不总是真实的。 出现这种情况,例如当图像注释器粗心或疲倦时,或者某些图像难以分类。
对于不完全监督,在这种情况下,我们只给予少量的训练数据,并且很难根据这样的小注释来训练良好的学习 然而,好的一面是我们有足够的未标注数据。 这种情况在实际应用中经常发生,因为注释的成本总是很高。
通过使用弱监督方法,我们尝试以最有效的方式利用这些未标注的数据。有两种主要方法可以解决这个问题,即主动学习和半监督学习。两者的明确区别在于前者需要额外的人为输入,而后者不需要人为干预。
主动学习(Active Learning)
主动学习假设可以向人类从查询未标注数据的 ground truth。目标是最小化查询的数量,从而最大限度地减少人工标签的工作量。换句话说,此方法的输出是:从所有未标注的数据中,找到最有效的数据点,最值得标注的数据点然后询问 ground truth。
例如,可能有一个距离决策边界很远的数据点,具有很高的正类可信度,标注这一点不会提供太多信息或改进分类模型。但是,如果非常接近分离阈值的最小置信点被重新标注,则这将为模型提供最多的信息增益。
更具体地说,有两种广泛使用的数据点选择标准,即信息性和代表性。信息性衡量未标注实例有助于减少统计模型的不确定性,而代表性衡量实例有助于表示输入模式结构的程度。
关于信息性,有两种主要方法,即不确定性抽样(Uncertainty sampling)和投票机制(query-by-committee)。 前者培训单个分类器,然后查询分类器 confidence 最低的未标注数据。 后者生成多个分类器,然后查询分类器最不相同的未标注数据。
关于代表性,我们的目标是通常通过聚类方法来利用未标注数据的聚类结构。
半监督学习(Semi-Supervised Learning)
另一方面,半监督学习则试图在不询问人类专家的情况下利用未标注的数据。 起初这可能看起来反直觉,因为未标注的数据不能像标注数据一样,直接体现额外的信息。
然而,未标注的数据点却存在隐含的信息,例如,数据分布。新数据集的不断增加以及获得标签信息的困难使得半监督学习成为现代数据分析中具有重要实际意义的问题之一。
半监督学习的最主要假设:数据分布中有可以挖掘的的信息。
总结
在深入了解弱监管的历史和发展之后,我们可以看到这一研究领域的局限性和改进潜力。数据标签成本总是很昂贵,因为需要领域专业知识并且过程非常耗时,尤其是在 NLP 中,文本理解因人而异。但是,我们周围存在大量(几乎无限量)未标注的数据,并且可以很容易地提取。
因此,我们始终将持续利用这种丰富资源视为最终目标,并试图改善目前的监督学习表现。从 ULMFiT 等语言模型到最近的 BERT,迁移学习是另一种利用未标注数据的方法。通过捕获语言的结构,本质上是另一种标签形式。在这里,我们建议未来发展的另一个方向 - 将迁移学习与半监督学习相结合,通过利用未标注的数据进一步提高效果。

发布时间:2019.10.17来源:知乎浏览量:201次
发布时间:2018.11.20来源:数据治理浏览量:190次
发布时间:2020.12.03来源:知乎浏览量:286次
发布时间:2018.11.29来源:数据治理浏览量:252次
发布时间:2022.02.23来源:浏览量:766次
发布时间:2022.05.27来源:小亿浏览量:356次
发布时间:2021.05.28来源:亿信数据治理知识库浏览量:235次
发布时间:2019.03.19来源:亿信华辰浏览量:197次
发布时间:2022.03.09来源:小亿浏览量:1422次
发布时间:2018.11.26来源:数据治理浏览量:184次
保存二维码微信扫一扫,立即在线咨询
人工
客服
预约
演示
您好,商务咨询请联系
400咨询:4000011866
技术
支持
您好,技术支持请联系
QQ:400-0011-866
(工作日9:00-18:00)